
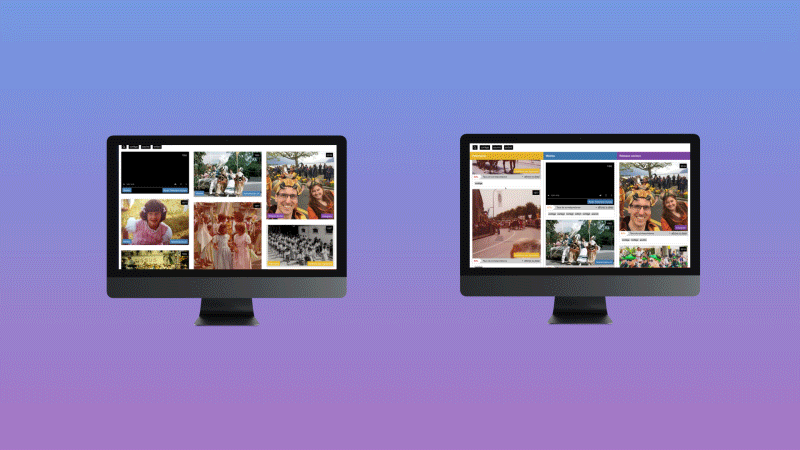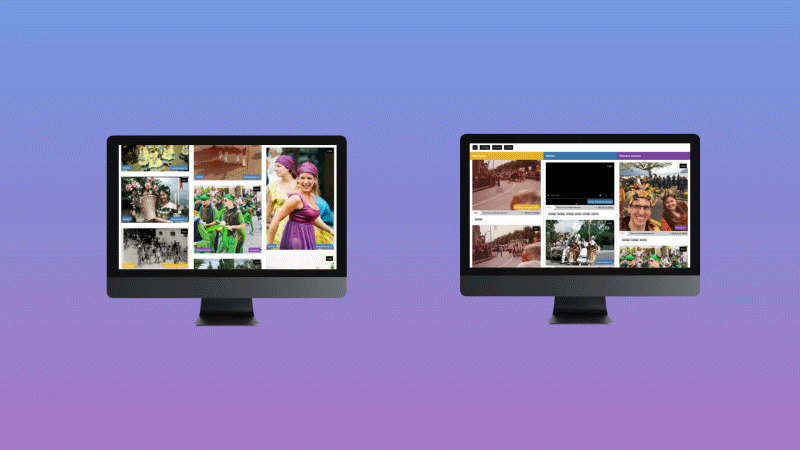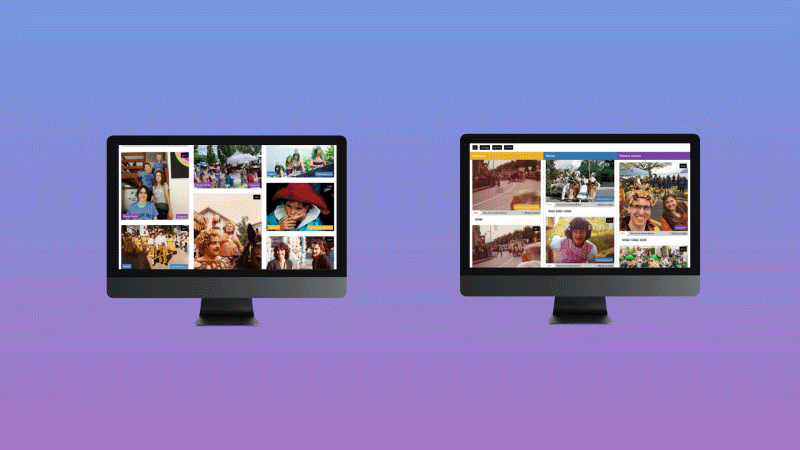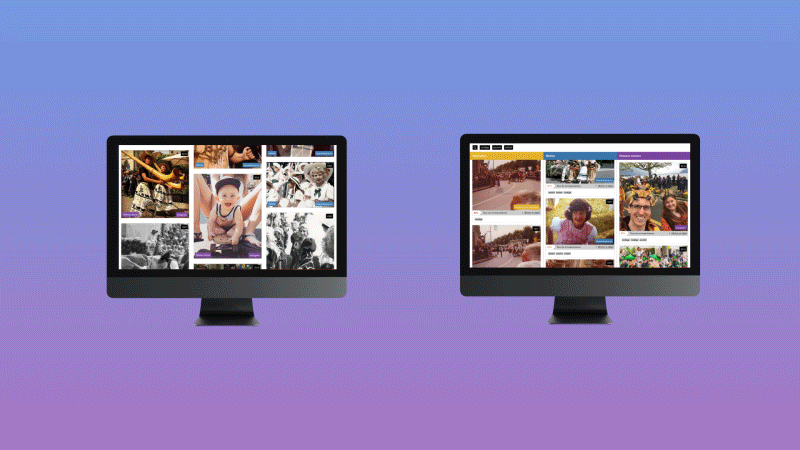



This project anticipates the growing risk for media outlets to publish erroneous information as they rely more and more on algorithms to produce and distribute their content. In particular, it aims to develop and evaluate a content aggregator based on machine learning that combines images from media sources, cultural archives and social networks, using a design approach that allows users to see in a transparent way the source of journalistic content, as well as the decisions made by algorithms, in order to increase their perception of trust.
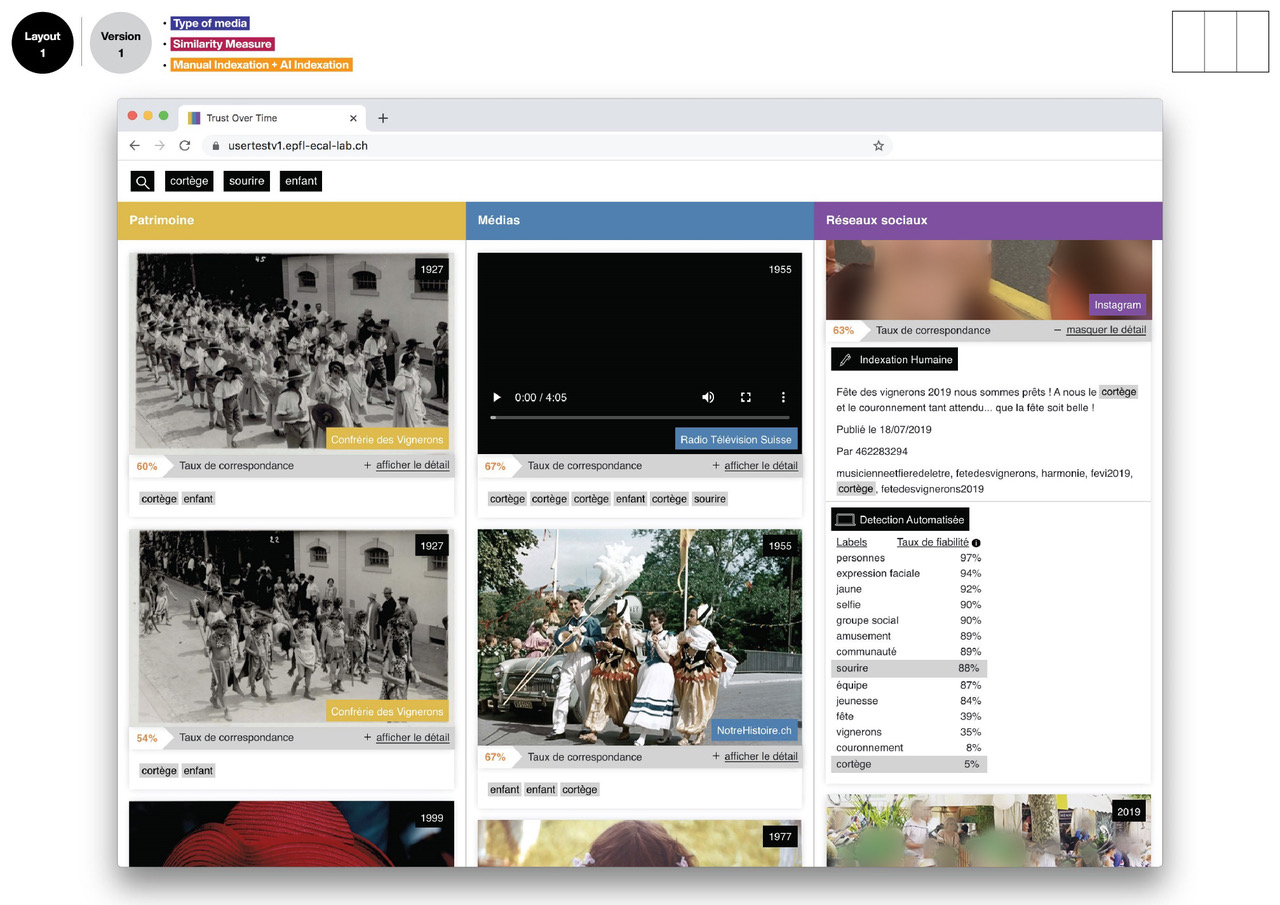
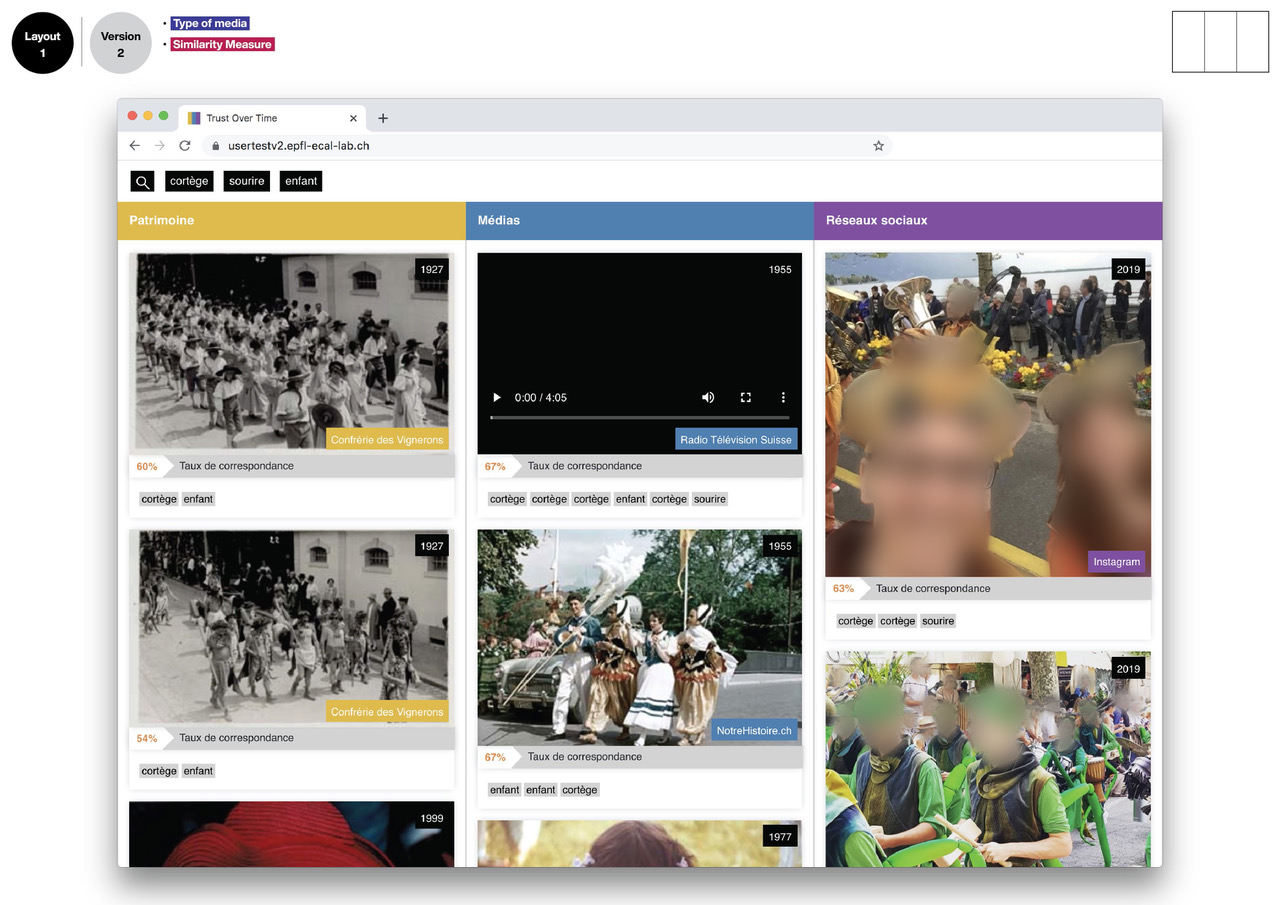
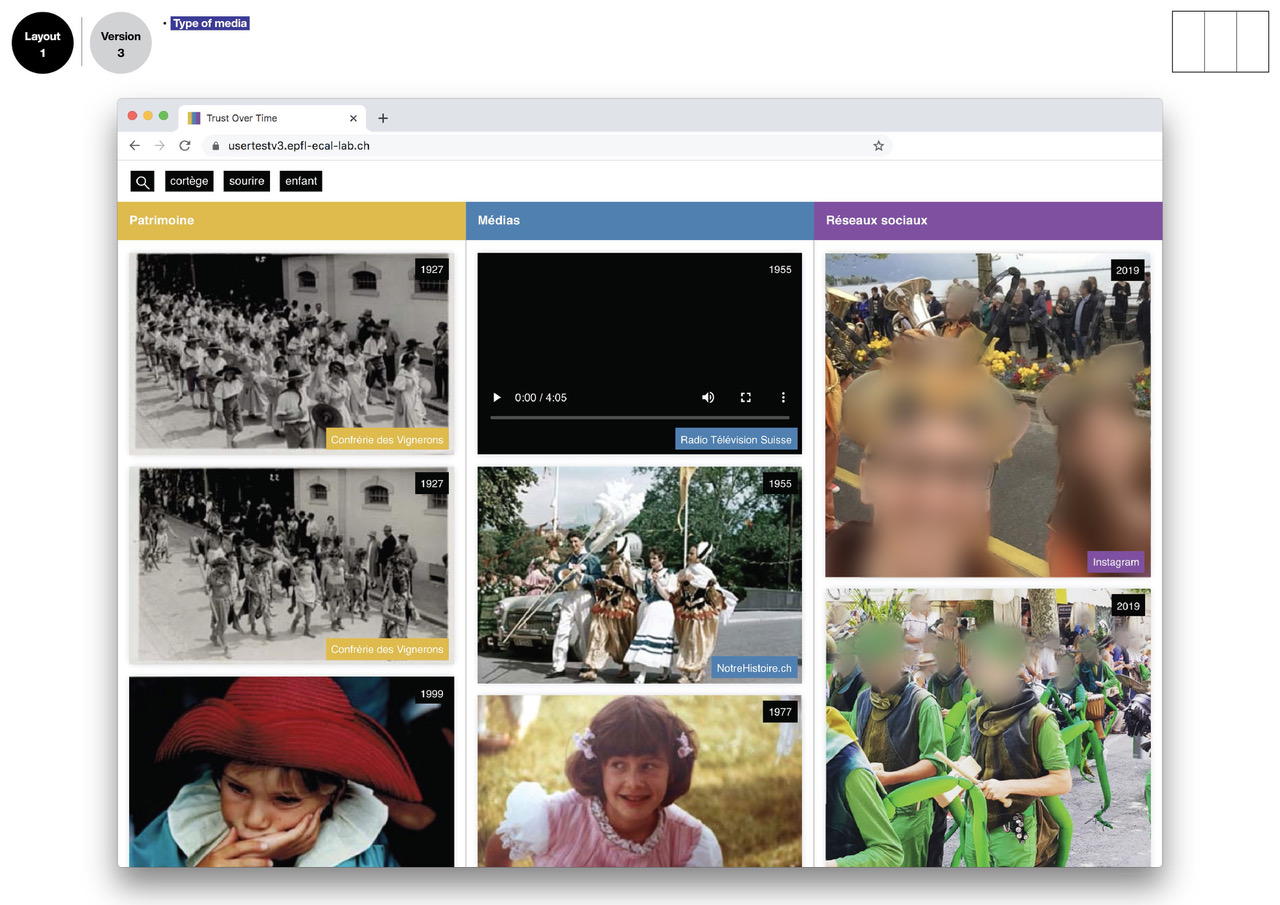
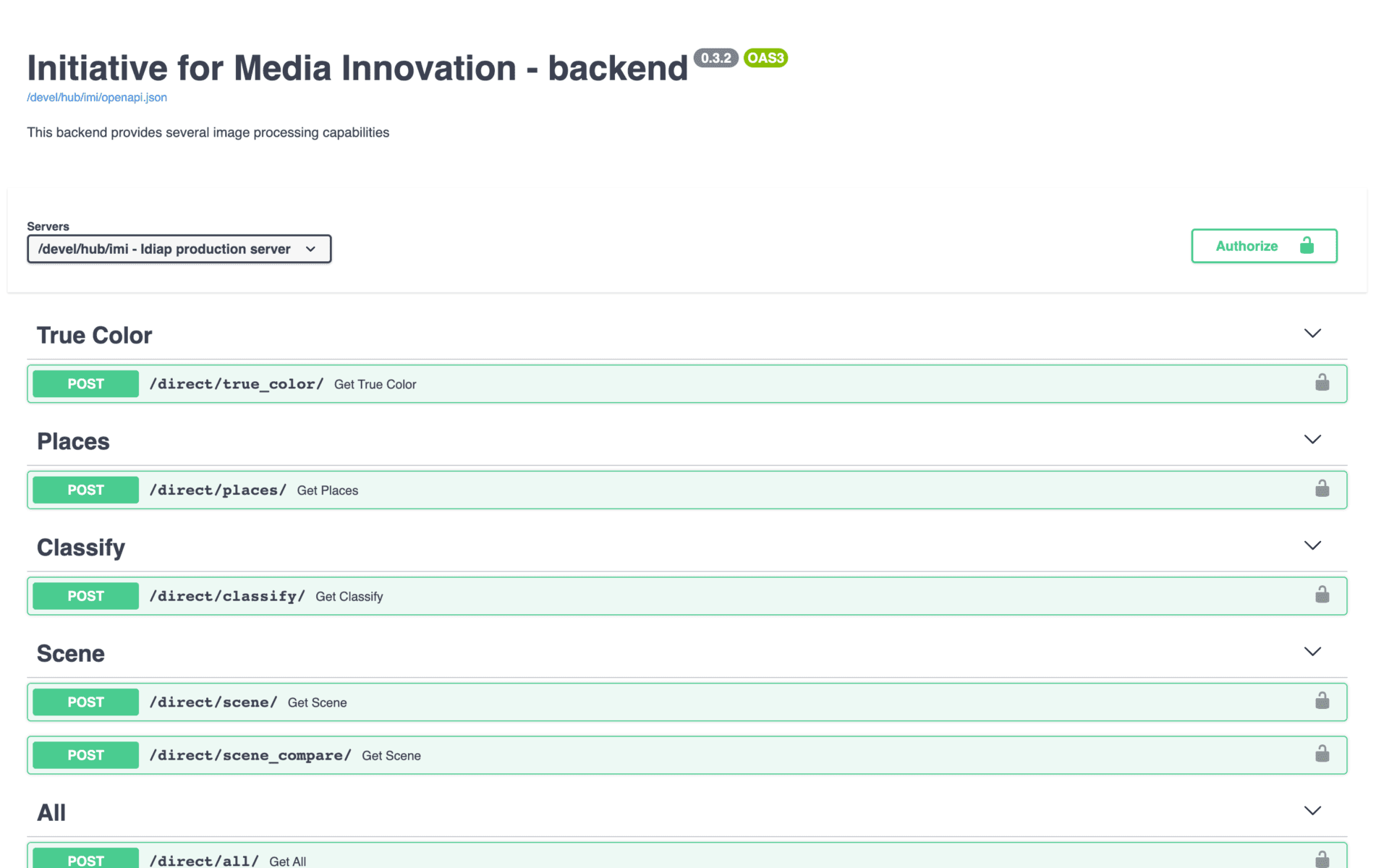
A RESTful web service has been developed to extract the probability distribution of a set of predefined visual features (512 true colors, 365 places, 1000 objects and 150 semantic scenes). Then a series of layouts and scenarios have been designed and tested with 266 participants to understand the impact of several pre-selected trust indicators (source, source type, similarity score, indexation details).
The results show the positive effect of layout structuration and hierarchization in highlighting trust indicators, but also the distrust of users when machine learning results are displayed as a simple percentage, demonstrating the urgent need to find engaging and trusting representations for machine learning algorithms.
Presentation of the project results at the IMI Annual Event (24.09.2020)
Watch on YouTube